Setup Hadoop(HDFS) on Mac
This tutorial will provide step by step instruction to setup HDFS on Mac OS.
Download Apache HadoopYou can click here to download apache Hadoop 3.0.3 version or go to Apache site http://hadoop.apache.org/releases.html to download directly from there. Move the downloaded Hadoop binary to below path & extract it.
$HOME/hadoop/
There are 6 steps to complete in order setup Hadoop (HDFS)
- Validate if java is installed
- Setup environment variables in .profile file
- Setup configuration files for local Hadoop
- Setup password less ssh to localhost
- Initialize Hadoop cluster by formatting HDFS directory
- Starting Hadoop cluster
-
Validating Java: Java version can be checked using below command. If java is not present or lower version(Java 8 is recommended) is installed then latest JDK can be download from Oracle site here and can be installed.
$ java -version Output: java version "1.8.0_141" Java(TM) SE Runtime Environment (build 1.8.0_141-b15) Java HotSpot(TM) 64-Bit Server VM (build 25.141-b15, mixed mode)
-
Set below variables in the .profile file in $HOME directory
Note: Path of Java Home can be determined by using below command in Terminal## Set Java Home as env variable export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_141.jdk/Contents/Home ## Set HADOOP environment variables export HADOOP_HOME=$HOME/hadoop/hadoop-3.0.3 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export YARN_HOME=$HADOOP_HOME export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_INSTALL=$HADOOP_HOME ## Set Path to the Hadoop Binary export PATH=$PATH:$HADOOP_HOME/bin
/usr/libexec/java_home
- In order to set HDFS, please make changes (as mentioned in detail below) in the following files under $HADOOP_HOME/etc/hadoop/
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- hadoop-env.sh
core-site.xml : Please add below listed XML properties in $HADOOP_HOME/etc/hadoop/core-site.xml file<!-- Place below properties inside configuration tag --> <!-- Specify the port for hadoop hdfs --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
hdfs-site.xml : Please add below listed XML properties in $HADOOP_HOME/etc/hadoop/hdfs-site.xml file<!-- Place below properties inside configuration tag --> <!-- Directory Path where hadoop file system will be created(create these hadoop_storage directory and specify the path) --> <property> <name>dfs.name.dir</name> <value>[$HOME Path]/hadoop/hadoop_storage</value> <final>true</final> </property> <!-- Default block size is 128 Mb --> <property> <name>dfs.blocksize</name> <value>134217728</value> </property> <!-- Replication factor is set as 1 as this is for local --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- Specify a particular Temporary directory, otherwise it will try to use defalut temp dir of system --> <property> <name>hadoop.tmp.dir</name> <value>[$HOME Path]/hadoop/tmp</value> </property> <!-- Below property is for hive setup --> <property> <name>hive.metastore.warehouse.dir</name> <value>hdfs://master:8020/user/hive/warehouse</value> </property>
yarn-site.xml : Please add below listed XML properties in $HADOOP_HOME/etc/hadoop/yarn-site.xml file<!-- Place below properties inside configuration tag --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME, HADOOP_COMMON_HOME, HADOOP_HDFS_HOME, HADOOP_CONF_DIR, CLASSPATH_PREPEND_DISTCACHE, HADOOP_YARN_HOME, HADOOP_MAPRED_HOME </value> </property> <!-- This property specify to show system healthy until capacity is reached 98.5% --> <property> <name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage </name> <value>98.5</value> </property>
mapred-site.xml : Please add below listed XML properties in $HADOOP_HOME/etc/hadoop/mapred-site.xml file<!-- Place below properties inside configuration tag --> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value> </property> <property> <name>mapred.job.tracker</name> <value>localhost:8021</value> </property>
hadoop-env.sh : Please add below environment variables in $HADOOP_HOME/etc/hadoop/hadoop-env.sh file# export JAVA_HOME [Same as in .profile file] export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_141.jdk/Contents/Home # Location of Hadoop. export HADOOP_HOME=[Download hadoop Binary path]
-
Hadoop namenode & secondary namenode requires password less ssh to localhost in order to start. 2 things need to be done to setup password less ssh.
- Enable Remote Login in System Preference --> Sharing, get your username added in allowed user list if you are not administrator of the system.
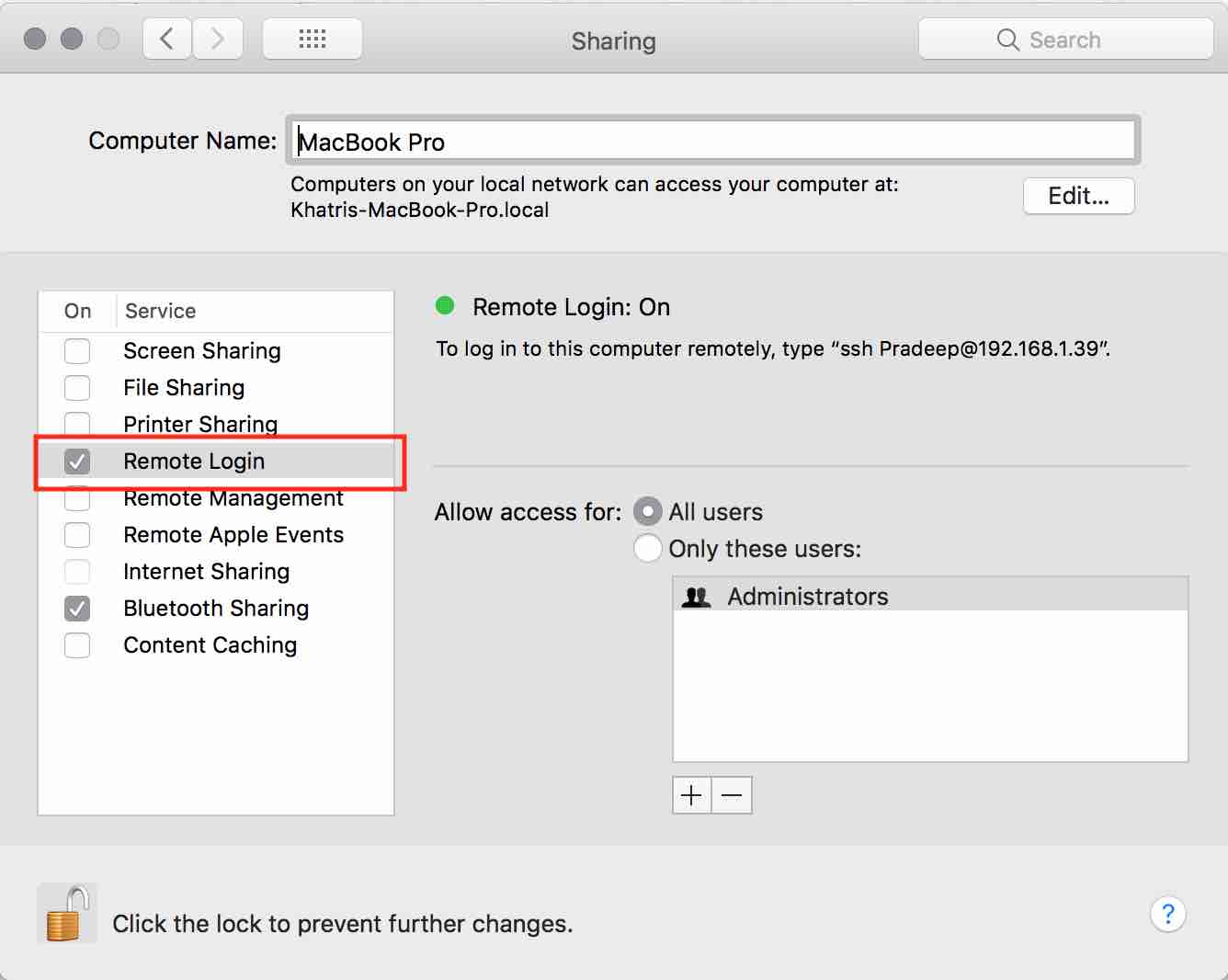
- Generate & setup key
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- Enable Remote Login in System Preference --> Sharing, get your username added in allowed user list if you are not administrator of the system.
- Initialize Hadoop cluster by formatting HDFS directory[Run below commands in terminal]
source ~/.profile $HADOOP_HOME/bin/hdfs namenode -format
- Starting Hadoop cluster
- Starting both hdfs & yarn servers in single command
$HADOOP_HOME/sbin/start-all.sh - Other Commands to start hdfs & yarn servers one by one.
$HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh
- Starting both hdfs & yarn servers in single command
Checking if all the namenode, datanode & resource manager started or not (using jps command)
$ jps
Output
2448 SecondaryNameNode
2646 ResourceManager
2311 DataNode
2746 NodeManager
2815 Jps
2207 NameNode
Health of the hadoop cluster & yarn processing can be checked on Web UI
Hadoop Health: http://localhost:9870
Yarn: http://localhost:8088/cluster
Stopping Hadoop cluster
- Stopping both hdfs & yarn servers in single command
$HADOOP_HOME/sbin/stop-all.sh - Other Commands to start hdfs & yarn servers one by one.
$HADOOP_HOME/sbin/stop-dfs.sh $HADOOP_HOME/sbin/stop-yarn.sh
Running Basic HDFS Command
- Hadoop Version
$ hadoop version Output: Hadoop 3.0.3 - List all directories
hadoop fs -ls / - Creating user home directory
hadoop fs -mkdir -p /user/[username] - Copy file from local to HDFS
hadoop fs -copyFromLocal $HADOOP_HOME/etc/hadoop/core-site.xml . hadoop fs -put $HADOOP_HOME/etc/hadoop/core-site.xml /user/[username]/output - Checking data in the file on HDFS
hadoop fs -cat hdfs://localhost:9000/user/[username]/output/part-r-00000